すべてのテキストを抽出したいPDFドキュメント(PDF document)がありますか?編集可能なテキストに変換したいスキャンしたドキュメントの画像ファイルはどうですか?これらは、ファイルを操作するときに職場で見た最も一般的な問題の一部です。
この記事では、 PDF(PDF)または画像からテキストを抽出するためのさまざまな方法について説明します。抽出結果は、 PDFまたは画像(PDF or image)のテキストの種類と品質(type and quality)によって異なります。また、使用するツールによって結果が異なるため、最良の結果を得るには、以下のオプションをできるだけ多く試してみることをお勧めします。
画像またはPDFからテキストを抽出する
開始する最も簡単で迅速な方法は、オンラインPDFテキスト(PDF text) 抽出サービス(extractor service)を試すことです。これらは通常無料で、コンピュータに何もインストールしなくても、探しているものを正確に提供できます。これが私が使用した2つで、非常に良い結果から優れた結果が得られました。
ExtractPDF

ExtractPDFは、PDFファイルから画像、(PDF file)テキスト、フォント(text and fonts)を取得するための無料のツールです。唯一の制限は、PDFファイルの(PDF file)最大サイズ(max size)が10MBであることです。それは少し小さいです。したがって、より大きなファイルがある場合は、以下の他の方法のいくつかを試してください。ファイルを選択し、[ファイルの送信(Send file)]ボタンをクリックします。通常、結果は非常に高速であり、[テキスト]タブ(Text tab)をクリックするとテキストのプレビューが表示されます。

また、必要な場合に備えて、 PDFファイル(PDF file)から画像を抽出することも利点です。全体として、オンラインツールはうまく機能しますが、面白い出力を提供するPDFドキュメントをいくつか見つけました。(PDF docs)テキストは問題なく抽出されますが、何らかの理由で、各単語の後に改行が入ります。(line break)短いPDFファイル(PDF file)の場合は大きな問題ではありませんが、テキストが多いファイルの場合は確かに問題になります。それが発生した場合は、次のツールを試してください。
オンラインOCR
オンラインOCRは通常、 (Online OCR)ExtractPDFで適切に変換されなかったドキュメントに対して機能する傾向があるため、両方のサービスを試して、どちらがより良い出力を提供するかを確認することをお勧めします。オンラインOCR(Online OCR)には、ドキュメント全体ではなく数ページのテキストを変換するだけでよい大きなPDFファイル(PDF file)を持っている人にとって便利ないくつかの優れた機能もあります。
最初にやりたいことは、先に進んで無料のアカウントを作成することです。少し面倒ですが、無料のアカウントを作成しないと、ドキュメント全体ではなく、 PDFの一部しか変換されません。(PDF)また、5 MBのドキュメント(MB document)しかアップロードできないのではなく、アカウントを使用してファイルごとに最大100MBをアップロードできます。

まず、言語を選択してから、変換されたファイルに使用する出力形式のタイプを選択します。いくつかのオプションがあり、必要に応じて複数を選択できます。[複数ページのドキュメント](Multipage document)で、[ページ番号(Page numbers)]を選択してから、変換するページのみを選択できます。次に、ファイル(file and click) を選択して[変換(Convert)]をクリックします。
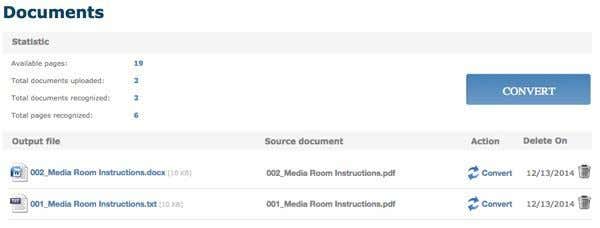
変換後、[ドキュメント(Documents)]セクション(ログインしている場合)が表示され、残りの利用可能な空きページの数と、変換されたファイルをダウンロードするためのリンクが表示されます。1日25ページしか無料ではないようです。それ以上必要な場合は、少し待つか、さらにページを購入する必要があります。
オンラインOCR(Online OCR)は、テキストの実際のレイアウトを維持することができたため、 PDFを変換する優れた仕事をしました。私のテストでは、箇条書きやさまざまなフォントサイズなどを使用したWord文書を取得し、 (Word doc)PDFに変換しました。次に、オンラインOCRを使用して(Online OCR)Word形式(Word format)に変換し直しましたが、元の形式と約95%同じでした。それは私にとってかなり印象的です。
さらに、画像をテキストに変換する場合、OnlineOCRは(Online OCR)PDFファイルからテキストを抽出するのと同じくらい簡単にそれを行うことができます。
無料のオンラインOCR
画像からテキストへのOCR(OCR)について話していたので、画像で非常にうまく機能する別の優れたWebサイトについて説明します。 テスト画像からテキストを抽出する場合、無料のオンラインOCR(Free Online OCR)は非常に優れていて非常に正確でした。iPhoneから本やパンフレットなどのページの写真を何枚か撮りましたが、テキストをうまく変換できたことに驚きました。

ファイルを選択し、[アップロード]ボタン(Upload button)をクリックします。次の画面には、いくつかのオプションと画像のプレビューがあります。全体をOCRしたくない場合は、トリミングできます。次に、[ OCR]ボタン(OCR button)をクリックするだけで、変換されたテキストが画像プレビュー(image preview)の下に表示されます。また、制限はありません。これは本当に素晴らしいことです。
オンラインサービスに加えて、変換を実行するためにコンピューター上でローカルに実行されているソフトウェアが必要な場合に備えて、 2つのフリーウェアPDFコンバーターについて言及したいと思います。(PDF)オンラインサービスでは、常にインターネット接続(Internet connection)が必要ですが、それがすべての人に可能であるとは限りません。しかし、フリーウェアプログラムからの変換の品質がWebサイトの変換の品質よりも大幅に悪いことに気づきました。
A-PDFテキストエクストラクタ
A-PDF Text Extractorは、PDFファイル(PDF file)からテキストを抽出するのにかなり良い仕事をするフリーウェアです。ダウンロードしてインストールしたら、[開く]ボタンをクリックし(Once)て(Open button)PDFファイル(PDF file)を選択します。次に、[テキストの抽出(Extract text)]をクリックしてプロセスを開始します。

テキスト出力ファイル(text output file)を保存する場所を尋ねられ、抽出が開始されます。[オプション(Option)]ボタンをクリックして、抽出する特定のページと抽出タイプ(extraction type)のみを選択することもできます。2番目のオプションは、さまざまなレイアウトでテキストを抽出するため興味深いものであり、3つすべてを試して、どれが最良の出力を提供するかを確認する価値があります。
PDF2Textパイロット
PDF2Text Pilot は、テキストを抽出するという大丈夫な仕事をします。オプションはありません。ファイルやフォルダを追加し、変換し(convert and hope)て、最高のものを期待するだけです。一部のPDF(PDFs)ではうまく機能しましたが、大部分のPDFには多くの問題がありました。
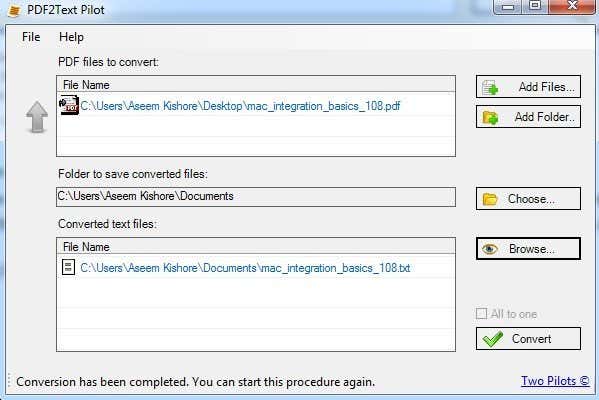
[ファイルの追加(Add Files)]をクリックしてから、[変換(Convert)]をクリックするだけです。変換が完了したら、[参照]をクリックして(Browse)ファイルを開きます。このプログラムを使用するとマイレージが異なりますので、あまり期待しないでください。
また、企業環境にいる場合、または仕事からAdobe Acrobatのコピーを手に入れることができる場合は、はるかに優れた結果を得ることができることにも言及する価値があります。Acrobatは明らかに無料ではありませんが、PDFをWord、Excel、およびHTML形式(Excel and HTML format)に変換するオプションがあります。また、元のドキュメントの構造を維持し、複雑なテキストを変換するのに最適です。
Extract Text from PDF and Image Files
Havе a PDF document that you wоuld like to extract all the text out of? What about image fіles of a scanned document that you want to convert into editable text? These are some of the most common issues I’ve seen at the workplace whеn working with files.
In this article, I’ll talk about several different ways you can go about trying to extract text from a PDF or from an image. Your extraction results will vary depending on the type and quality of the text in the PDF or image. Also, your results will vary depending on the tool you use, so it’s best to try out as many of the options below as possible to get the best results.
Extract Text from Image or PDF
The simplest and quickest way to start is to try an online PDF text extractor service. These are normally free and can give you exactly what you are looking for without having to install anything on your computer. Here are two that I have used with very good to excellent results:
ExtractPDF
ExtractPDF is a free tool to grab images, text and fonts out of a PDF file. The only limitation is that the max size for the PDF file is 10 MB. That’s a bit small; so if you have a bigger file, try some of the other methods below. Choose your file and then click the Send file button. The results are normally very fast and you should see a preview of the text when you click on the Text tab.
It is also a nice added benefit that it extracts images out of the PDF file too, just in case you need those! Overall, the online tool works great, but I have run into a couple of PDF docs that give me funny output. The text is extracted just fine, but for some reason it’ll have a line break after each word! Not a huge problem for a short PDF file, but certainly an issue for files with lots of text. If that happens to you, try the next tool.
Online OCR
Online OCR usually tended to work for the documents that didn’t convert properly with ExtractPDF, so it’s a good idea to try both services to see which ones gives you better output. Online OCR also has some nicer features that can prove handy for anyone with a large PDF file that only needs to convert text on a few pages rather than the whole document.
The first thing you want to do is go ahead and create a free account. It’s a bit annoying, but if you don’t create the free account, it will only partially convert your PDF rather than the entire document. Also, instead of only being able to upload only a 5 MB document, you can upload up to 100MB per file with an account.
First, choose a language and then pick the type of output formats you would like for the converted file. You have a couple of options and you can choose more than one if you like. Under Multipage document, you can select Page numbers and then choose only the pages that you want to convert. Then you select the file and click Convert!
After conversion, you’ll be brought to the Documents section (if you’re logged in) where you can see how many available free pages you have left and links to download your converted files. It seems like you only have 25 pages for free a day, so if you need more than that, you’ll have to either wait a bit or buy more pages.
Online OCR did an excellent job of converting my PDFs because it was able to maintain the actual layout of the text. In my test, I took a Word doc that used bullets, different font sizes, etc and converted it to a PDF. Then I used Online OCR to convert it back to Word format and it was about 95% the same as the original. That’s pretty impressive for me.
Plus, if you are looking to convert an image to text, then Online OCR can do that just as easily as extracting text from PDF files.
Free Online OCR
Since were talking about image to text OCR, let me mention another good website that works really well on images. Free Online OCR was very good and very accurate when extracting text from my test images. I took a couple of photos from my iPhone of pages from books, pamphlets, etc and I was surprised at how well it was able to convert the text.
Choose your file and then click the Upload button. On the next screen, there are a couple of options and a preview of the image. You can crop it if you don’t want to OCR the whole thing. Then just click the OCR button and your converted text will appear below the image preview. It also doesn’t have any limitations, which is really nice.
In addition to the online services, there are two freeware PDF converters I want to mention in case you need software running locally on your computer to perform the conversions. With online services, you’ll always need an Internet connection and that may not be possible for everyone. However, I noticed that the quality of the conversions from the freeware programs were significantly worse than those of the websites.
A-PDF Text Extractor
A-PDF Text Extractor is freeware that does an fairly good job of extracting text from PDF files. Once you download it and install it, click the Open button to choose your PDF file. Then click Extract text to start the process.
It’ll ask you a location to store the text output file and then it will begin extracting. You can also click on the Option button, which lets you choose only certain pages to extract and the extraction type. The second option is interesting because it extracts the text in different layouts and it’s worth trying all three to see which ones gives you the best output.
PDF2Text Pilot
PDF2Text Pilot does an ok job of extracting text. It doesn’t have any options; you just add files or folders, convert and hope for the best. It worked well on some PDFs, but for the majority of them, there were numerous issues.
Just click Add Files and then click Convert. Once the conversion is complete, click on Browse to open the file. You mileage will vary using this program so don’t expect much.
Also, it’s worth mentioning that if you are in a corporate environment or can get your hands on a copy of Adobe Acrobat from work, then you can really get much better results. Acrobat is obviously not free, but it has options to convert PDF to Word, Excel and HTML format. It also does the best job of maintaining the structure of the original document and converting complicated text.
