私たちの多くは、ハードディスクまたはSSDの障害を経験しています。私たちの中には、ハードドライブの信頼性と、 SMART(SMART)と呼ばれるテクノロジーの一部である隠された予測機能(hidden prediction function)についてもっと調べようとした人もいます。SMARTは、すべての場合に障害を予測するわけではないほど信頼性が低いと主張する人もいるかもしれません。この事実は部分的には真実ですが、この自己監視システムの実際の内部動作はそれほど単純ではないので、SMARTがどのように機能するかを調べてみましょう。また、 HDD SMARTステータス(HDD SMART status)、およびソリッドステートドライブのSMARTステータス(SMART status)を確認する方法についても説明します。
SMART(HDD&SSD)とは何ですか?
SMARTは、ドライブの内部情報を監視するシステムです。(SMART is a system that monitors the internal information of your drive.)その巧妙な名前は、実際には(clever name)Self-Monitoring、Analysis、andReportingTechnologyの頭字語です。SMARTは、 (SMART)SMARTとも呼ばれ、 HDDおよびSSD(HDDs and SSDs)内にあるテクノロジーです。これは、オペレーティングシステム(operating system)、BIOS、またはその他のソフトウェアから独立しています。
SMARTはHDDとSSD(HDDs and SSDs)に対して何をしますか?
SMARTが発明されたのは、コンピューターがハードドライブの状態(health state)を監視できるものを必要としていたためです。つまり、簡単に言えば、SMARTは、ハードドライブまたはソリッドステートドライブが動作を停止しようとしているかどうかを通知できるはずです(SMART should supposedly be able to tell you if your hard drive or solid-state drive is about to stop working)。

SMARTはどのようにそれを行いますか?SMARTは、ドライブが正常であるかどうかを魔法のように推測できると考えたくなるかもしれません。🙂しかし、それが行うことはまったく別の話です。SMARTは、ドライブごとに数とタイプが異なる一連の変数を追跡します。これらの変数(SMART keeps track of a series of variables)は、その信頼性の指標です(indicators of its reliability)。約50個のSMART属性(生の読み取りエラー率(error rate)、スピンアップ時間、報告された修正不可能なエラー、電源投入時間、ロードサイクル数(cycle count)など)があるため、すべてのSMART属性の詳細を知りたい場合。 、このWebページにアクセスしてください(visit this webpage)。
ただし、いくつかの特異な試み(Google、Backblaze)を除いて、ほとんどのSMARTは知っています。データは文書化されていません。システムは大量の内部データを提供します。それでも、ハードドライブメーカーの多くは異なる定義と測定値を使用しているため、統計には多くの矛盾があります。たとえば、一部のメーカーは電源オン時間データを時間として保存しますが、他のメーカーはそれを数分または数秒で測定します。また、さまざまな属性または変数のどれが注目に値するかを説明していないため、データに溺れてしまいます。
どのSMART(SMART)属性が関連しているかを理解する前に、まず、 SSDとHDDの障害の主なタイプ(予測可能と予測不可能(SSD and HDD failures: predictable and non-predictable))を区別する必要があります。

予測可能な障害(Predictable failures)には、時間内に発生し、ディスクメカニズムの障害、またはハードディスクの場合はディスクの表面の損傷によって引き起こされる故障が含まれます。ソリッドステートドライブの場合、予測可能な障害には、時間の経過に伴う通常の摩耗や、失敗した多数の消去試行が含まれる可能性があります。問題(Problems)は時間の経過とともに悪化し、ドライブは最終的に故障します。
予測できない障害(Non-predictable failures)は突然のイベントによって引き起こされます。たとえば、突然の電力サージや、ハードディスクまたはソリッドステートドライブ内の回路への予期しない損傷などがあります。理解しておくべき重要なことは、SMARTは予測可能な障害の検出にしか役立たない(S.M.A.R.T. can only help you detect predictable failures)ということです。
SMARTとは何か、およびその機能についての基本的な理解ができたので、 WindowsからドライブのSMARTステータスを確認する方法と、 (SMART status)SMARTの詳細を読み取って解釈する方法を見てみましょう。
SSDおよびHDDSMARTステータス(SSD and HDD SMART status)を確認する方法
Windowsコンピュータおよびデバイスでは、ハードディスクまたはSSDからSMARTデータを読み取る最も簡単な方法は(Windows)、専用(SSD)の(SMART)アプリを使用することです。そこにはかなりの数がありますが、それらの多くは開発が不十分であるか、費用がかかります(cost money)。SMARTデータを読み取ることができるすべてのアプリの中で、CrystalDiskInfoを使用することをお勧めします。これは無料で、SMART属性を読み取ることができます。また、 (SMART)IDE(PATA)、SATA、NVMeの両方からSMARTデータを取得できる数少ないアプリの1つでもあります。ドライブ、およびe SATA(SATA)、USB、またはIEEE1394を使用しているポータブルドライブから。

HDDまたはSSD(HDD or SSD)のSMARTステータスと詳細(SMART status and details)を確認するもう1つの優れた方法は、製造元が提供するアプリを使用することです。たとえば、ほとんどのソリッドステートドライブには、ドライブに関する情報の確認、状態の確認、診断の実行などを可能にするサポートアプリが付属しています。(support apps)これらのアプリには通常、SMARTステータス(SMART status)を確認するためのオプションが含まれています。
ハードディスクドライブまたはSSDの(disk drive or SSD)SMARTステータス(SMART status)を確認する3番目の方法は、 Windows10によって提供されます。詳細は表示されませんが、ドライブのSMARTステータス(SMART status)がOKかどうかはわかります。SMARTを確認するには、コマンドプロンプト(Command Prompt)を開き、次のコマンドを実行します:wmic diskdrive get model、status。このコマンドは、PCに接続されているドライブのリストを出力し、各ドライブのSMARTステータス(SMART status)を表示します。
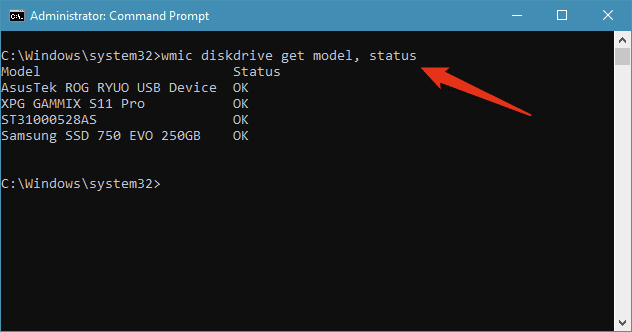
SMARTステータス(SMART status)を確認するこの最後の方法は、ドライブに障害が発生しているかどうかを確認するためのWindows10での最も簡単な方法です。
SSDまたはHDDSMARTテストを実行する方法
ドライブのSMARTステータス(SMART status)を読み取るだけでは満足できない場合は、 SSDまたはHDDのSMARTテスト(SSD or HDD SMART test)を実行することもできます。この目的のために専用のアプリが必要なので、言うのは簡単です。したがって、これは別の記事に値する主題であると考えました。このリンクからアクセスできます。HDDまたはSSD(HDD or SSD)をテストし、そのヘルスステータス(health status)を確認します。
SMART値と属性の読み方
ハードディスクのヘルスステータスは、複数のセンサーで継続的にテストおよび監視されます。(health status)値は一般的なアルゴリズムを使用して測定され、対応する属性は結果に応じて微調整されます。
SMART監視プログラム(monitoring program)では、次のフィールドの少なくとも一部を含む属性が表示されます。
-
識別子:(Identifier:)属性の定義。通常は標準的な意味があり、1〜250の数字でマークされます(たとえば、9はパワーオンカウント(Power-on Count)です)。それでも、すべてのディスク監視およびテストツール(disk monitoring and testing tools)は、属性の名前とテキストによる説明を提供します。
-
しきい値:(Threshold:)属性の最小値。この値に達すると、ドライブに障害が発生しそうになります。
-
値:(Value:)属性の現在の値。アルゴリズムは、生データに基づいてこの数値を計算します。新しいハードドライブの数は、理論上の最大値(製造元によっては、100、200、または253)であり、その寿命の間に減少するはずです。
-
最悪:(Worst:)これまでに記録された属性の最小値。
-
データ:(Data:)センサーまたはカウンターによって提供される生の測定値。これは、 HDDまたはSSD(HDD or SSD)の製造元によって設計されたアルゴリズムによって使用されるデータです。その内容は、ドライブの属性とメーカーによって異なります。通常のユーザーはこれをスキップする必要があります。
-
フラグ:(Flags:)属性の目的。これは通常、製造元によって設定されるため、ドライブごとに異なります。(manufacturer and therefore varies)各属性は重要であり、差し迫った障害を予測できる(たとえば、ID 5の再割り当てされたセクター数)か、ステータスに直接影響を与えない統計的(たとえば、ID 174の予期しない電力損失数(power loss count))です。

SMART属性のステータスを理解しようとするときは、値、しきい値、フラグの3つのフィールドの値を確認してください(to understand the status of any S.M.A.R.T. attribute, check the values of these three fields: value, threshold, and flags)。また、通常、値が小さいほど信頼性が低下していることを示していることを(smaller values are an indication of a decrease in reliability)忘れないでください。
SMARTを使用してHDDまたはSSD(HDD or SSD)の障害を予測する方法(確認する必要のある値)
すべてのSMARTではありません。属性は障害予測(failure prediction)にとって重要です。ハードドライブの故障(drive failure)率とその他の情報源に関する上記の2つの研究は、故障したドライブを特定する上での重要な助けは次のとおりであることに同意しています。
-
再割り当てされたセクター数(Reallocated sector counts)。再割り当ては、ドライブのロジックが、繰り返し発生するソフトエラーまたはハードエラーの結果として、損傷したセクターをスペアセクターから新しい物理セクターに再マップするときに発生します。この属性は、再マッピングが発生した回数を反映しています。その値が増加する場合は、HDDまたはSSDの摩耗を示しています。
-
現在保留中のセクター数(Current Pending Sector Count)。これは「不安定な」セクターをカウントします。これは、一種の「保護観察」システムである再マッピングを待機している読み取りエラーのある損傷したセクターを意味します。SMARTアルゴリズムは、説得力がない場合があるため、この特定の属性についてさまざまな理解を持っています。それでも、起こりうる問題を早期に警告することができます。
-
報告された修正不可能なエラー(Reported Uncorrectable Errors)。回復できないエラーの数であり、すべてのメーカーで同じ意味を持っているように見えるので便利です。
-
失敗カウントを消去し(Erase Fail Count)ます。これは、ソリッドステートドライブの早期死亡の優れた指標です。失敗したデータ削除の試行回数をカウントし、値が増加すると、SSD内のフラッシュメモリが寿命に近づいていることを示します。
-
ウェアレベリングカウント(Wear Leveling Count)。これは、SSDにも特に役立ちます。メーカーは、SSDの予想寿命をSMARTデータに設定しています。ウェアレベリングカウント(Wear Leveling Count)は、ドライブの状態の推定値です。これは、事前定義された予想寿命と、各メモリフラッシュブロックが寿命に達する前に実行できるサイクル数(書き込み、消去など)を考慮したアルゴリズムを使用して計算されます。
-
ディスク温度(Disk temperature)は非常に議論されているパラメータです。それでも、60°Cを超える値はHDDまたはSSDの寿命を縮め、損傷の可能性を高める可能性があると考えられています。ドライブの温度を下げ、できればドライブの寿命を延ばすために、ファンを使用することをお勧めします。
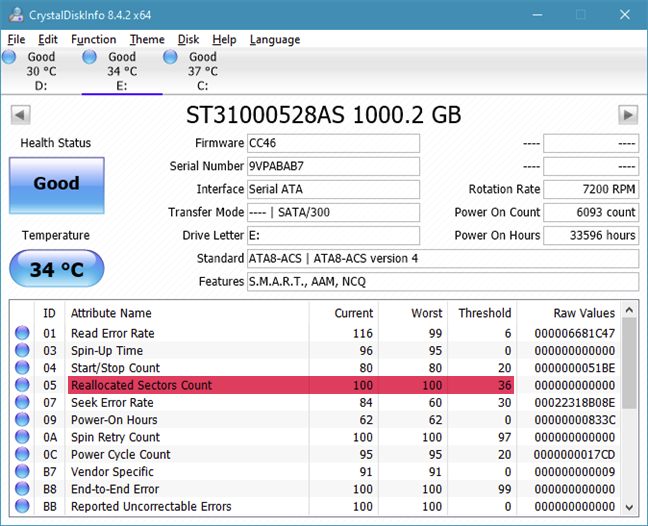
上記のSMART。属性は比較的簡単に解釈できます。それらの値の増加に気付いた場合は、ドライブに障害が発生している可能性があるため、バックアップを開始することをお勧めします。ただし、これらはドライブの信頼性の有用な指標ですが、絶対確実ではないことを忘れないでください。
SMARTに関する歴史的メモ
SMARTは、 (SMART)1992年(year 1992)から開発されましたが、現在では、すべての最新のソリッドステートドライブとハードディスクドライブに含まれていることがわかります。その歴史は、Predictive Failure AnalysisやIntelliSafeなどの一連の名前と、 (Predictive Failure Analysis or IntelliSafe)IBM、Seagate、Quantum、WesternDigitalなどのすべての主要なハードディスクメーカーからの入力を網羅しています。最後に、そのドキュメントは2004年にParallel ATA(Parallel ATA)標準内で初めて取り上げられ、その後定期的に改訂されました。最新のものは2011年に発行されました。
SSDとHDDSMART(SSD and HDD SMART)について他に知りたいことはありますか?
これは、 SMART(S.M.A.R.T)の内部動作と、ハードディスクの障害を監視、テスト、および予測する機能に関する短い調査でした。覚えておくべき主な観点は、この自己監視システムがHDDの(HDD)状態(health status)を確認するのに役立つということです。このSMARTデータ(S.M.A.R.T data)を使用して、自分のドライブに問題があるかどうかを確認する場合は、このチュートリアルで推奨されている記事をお読みください。また、質問については、以下のコメントフォームを使用して、話し合いましょう。
What is SMART and how to use it to predict HDD or SSD failure
A lot of us have experienced a hard disk or аn SSD failure. Some of υs have evеn tried to fіnd out more about the reliability of hard drіves and their hidden рrediction function that's part of a technolоgy сalled SMART. One mіght argue that SMART is not as reliable aѕ it does not рredіct failure in all casеs. This fact is partly true, but the actual inner workings of this self-monitoring system are not so sіmple, so lеt's examine how SMART works. We're also going to show you how to cheсk the HDD SMARΤ status, as well as the solid-ѕtate drive SMARΤ status:
What is SMART (HDD & SSD)?
SMART is a system that monitors the internal information of your drive. Its clever name is actually an acronym for Self-Monitoring, Analysis, and Reporting Technology. SMART, also written as S.M.A.R.T., is a technology found inside HDDs and SSDs. It is independent of your operating system, BIOS, or other software.
What does SMART do for HDDs and SSDs?
SMART was invented because computers needed something that could monitor the health state of their hard drives. That means, plainly speaking, that SMART should supposedly be able to tell you if your hard drive or solid-state drive is about to stop working!
How does SMART do that? You might be tempted to think that SMART can magically guess if your drive is healthy. 🙂 What it does is an entirely different story, though. SMART keeps track of a series of variables whose number and type vary from drive to drive, which are indicators of its reliability. If you want to get an in-depth idea of all the SMART attributes, as there are about 50 of them (raw read error rate, spin-up time, reported uncorrectable errors, power-on time, load cycle count, etc.), visit this webpage.
However, know that, apart from some singular attempts (Google, Backblaze), most of the S.M.A.R.T. data is undocumented. The system provides a great deal of internal data. Still, there are many inconsistencies in the statistics because many of the hard drive manufacturers use different definitions and measurements. For example, some manufacturers store power on-time data as hours, while others measure it in minutes or seconds. Also, they don't explain which of the various attributes or variables are worth our attention, making us drown in data.
Before attempting to understand which SMART attributes are relevant, we first have to differentiate between the main types of SSD and HDD failures: predictable and non-predictable.
Predictable failures include the breakdowns that appear in time and are caused by faulty disk mechanics or damages of the disk's surface in the case of hard-disks. For solid-state drives, predictable failures can include normal wear over time or a high number of erasing attempts that have failed. Problems get worse over time, and the drive eventually fails.
Non-predictable failures are caused by sudden events, of which we can mention, for example, sudden power surges or unexpected damage to circuitry inside the hard disk or solid-state drive. What is important to understand is that S.M.A.R.T. can only help you detect predictable failures.
Now that you have a basic understanding of what SMART is and does, let's see how to check the SMART status of your drives from Windows and then also how to read and interpret the SMART details:
How to check SSD and HDD SMART status
On Windows computers and devices, the easiest way to read SMART data from a hard disk or from an SSD is by using specialized apps. There are quite a few out there, but many of them are either poorly developed or cost money. Out of all the apps that can read SMART data, the best and the one that we're recommending that you use is CrystalDiskInfo. It is free, able to read SMART attributes, and it's also one of the few such apps that can get SMART data both from IDE(PATA), SATA, and NVMe drives, as well as from portable drives that are using eSATA, USB, or IEEE 1394.
Another excellent method of checking the SMART status and details of an HDD or SSD is to use the apps provided by its manufacturer. For example, most solid-state drives are accompanied by support apps that let you check information about them, check their health, run diagnostics, and so on. These apps usually include options for checking SMART status.
A third way of checking the SMART status of your hard disk drive or SSD is offered by Windows 10. It doesn't show details, but can tell you whether the SMART status of your drives is OK or not. To check SMART, open Command Prompt and run this command: wmic diskdrive get model, status. The command outputs the list of drives connected to your PC and shows the SMART status for each of them.
This last method to check the SMART status is probably the quickest way in Windows 10 to check whether your drives are failing.
How to run an SSD or HDD SMART test
If you're not satisfied with just reading the SMART status of your drives, you can also run an SSD or HDD SMART test. That is easier said than done because you need a specialized app for this purpose. Accordingly, we considered that this is a subject worthy of a separate article, which you can access via this link: Test your HDD or SSD and check its health status.
How to read SMART values and attributes
The health status of the hard disk is continuously tested and monitored with multiple sensors. The values are measured by the use of typical algorithms, and then the corresponding attributes are tweaked according to the results.
In any SMART monitoring program, you should see attributes that contain at least some of these fields:
-
Identifier: the definition of the attribute. It usually has a standard meaning, and it is marked with a number between 1 and 250 (for example, 9 is Power-on Count). Still, all disk monitoring and testing tools provide the name and a textual description of the attribute.
-
Threshold: the minimum value for the attribute. If this value is reached, then your drive is about to fail.
-
Value: current value of the attribute. The algorithm calculates this number based upon the raw data. A new hard drive should have a high number, the theoretical maximum (100, 200, or 253 depending on the manufacturer), that decreases during its lifetime.
-
Worst: the smallest value of the attribute ever recorded.
-
Data: raw measured values provided by a sensor or a counter. This is the data used by the algorithm designed by the manufacturer of the HDD or SSD. Its contents depend on the attribute and the maker of the drive. Regular users should skip this one.
-
Flags: the purpose of the attribute. This is usually set by the manufacturer and therefore varies from drive to drive. Each of the attributes is either critical and can predict an imminent failure (for example, ID 5 reallocated sectors count), or statistical with no direct effect on status (for example, ID 174 unexpected power loss count).
When trying to understand the status of any S.M.A.R.T. attribute, check the values of these three fields: value, threshold, and flags. Also, remember that, usually, smaller values are an indication of a decrease in reliability.
How to use SMART to predict the failure of an HDD or SSD (essential values to check)
Not all S.M.A.R.T. attributes are critical for failure prediction. The two above mentioned studies on hard drive failure rates and other sources agree that an important help in identifying failing drives are:
-
Reallocated sector counts. Reallocation happens when the drive's logic remaps a damaged sector, as a result of recurring soft or hard errors, to a new physical sector from its spare ones. This attribute reflects the number of times a remapping has happened. If its value increases, it's an indication of HDD or SSD wear.
-
Current Pending Sector Count. This counts the "unstable" sectors, meaning the damaged ones with read errors that are waiting for a remapping, a kind of "probation" system. S.M.A.R.T. algorithms have mixed understandings about this particular attribute, as it is sometimes unconvincing. Still, it can provide an earlier warning of possible problems.
-
Reported Uncorrectable Errors. It is the count of errors that are impossible to recover, and it is useful because it seems to have the same meaning for all manufacturers.
-
Erase Fail Count. This one is an excellent indicator of the premature death of a solid-state drive. It counts the number of failed data deletion attempts, and a value that increases tells you that the flash memory inside the SSD is close to its end-of-life.
-
Wear Leveling Count. This is also especially useful for SSDs. Manufacturers set the expected lifetime of an SSD in its SMART data. The Wear Leveling Count is an estimation of the health of your drive. It is calculated using an algorithm that takes into account the predefined expected lifetime and the number of cycles (write, erase, etc.) that each memory flash block can perform before reaching its end-of-life.
-
Disk temperature is a highly debated parameter. Still, it is considered that values above 60°C can reduce the lifespan of an HDD or SSD and increase the probability of damage. We recommend using a fan to decrease the temperature of your drives and hopefully prolong their life.
The above mentioned S.M.A.R.T. attributes are relatively easy to interpret. If you notice an increase in their values, it is possible that your drive is failing, so you'd better start backing up. However, although these are useful indicators of drive reliability, do not forget that they are not foolproof.
Historical note about SMART
SMART was developed beginning with the year 1992, although you know now that it is included by all modern solid-state drives and hard disk drives. Its history covers an array of names like Predictive Failure Analysis or IntelliSafe and input from all the major hard disk manufacturers: IBM, Seagate, Quantum, Western Digital. Finally, its documentation was featured for the first time in 2004 within the Parallel ATA standard and received regular revisions afterward. The latest one was issued in 2011.
Is there anything else you would like to know about SSD and HDD SMART?
This was our short study on the inner workings of S.M.A.R.T and its abilities to monitor, test, and predict hard disk failures. The main point of view you should remember is that this self-monitoring system can help you review the health status of your HDD. If you want to use this S.M.A.R.T data to see if your own drive has problems, read the articles we recommended in this tutorial. Also, for questions, use the comments form below, and let's discuss.
