テキストに変換したいPDFドキュメント(PDF document)または画像がありますか?最近、誰かが私にメールでドキュメントを送ってくれました。私はそれを編集して修正して送り返す必要がありました。その人はデジタルコピーを見つけることができなかったので、私はそのすべてのテキストをデジタル形式にするという任務を負いました。
何時間もかけてすべてを入力し直す方法がなかったので、最終的にドキュメントの高品質な写真を撮り、一連のオンラインOCRサービスを調べて、どれが最適かを確認しました。結果。
この記事では、無料のOCR用のお気に入りのサイトをいくつか紹介します。これらのサイトのほとんどは基本的な無料サービスを提供しており、より大きな画像、複数ページのPDF(PDF)ドキュメント、さまざまな入力言語などの追加機能が必要な場合は、有料のオプションが用意されていることに注意してください。
これらのサービスのほとんどは、元のドキュメントのフォーマットと一致しないことを事前に知っておくこともお勧めします。これらは主にテキストを抽出するためのものであり、それだけです。すべてを特定のレイアウトまたは形式にする必要がある場合は、 (layout or format)OCRからすべてのテキストを取得したら、手動で行う必要があります。
さらに、テキストを取得するための最良の結果は、200〜400DPIの解像度(DPI resolution)のドキュメントから得られます。DPI画像(DPI image)が低い場合、結果はそれほど良くありません。
最後に、私(t work)がテストしたサイトの中には、機能しなかったものがたくさんありました。Googleで無料のオンラインOCRを使用すると、多数のサイトが表示されますが、上位10件の結果に含まれるサイトのいくつかは変換を完了していません。タイムアウトするものもあれば、エラーが発生するものもあり、「変換」ページでスタックするものもあるので、これらのサイトについては言及しませんでした。
各サイトについて、2つのドキュメントをテストして、出力がどの程度良好になるかを確認しました。私のテストでは、iPhone 5Sを使用して両方のドキュメントの写真を撮り、それらをWebサイトに直接アップロードして変換しました。
私がテストに使用した画像がどのように見えるかを確認したい場合は、ここにそれらを添付しました:Test1とTest2。これらは、電話から取得した画像のフル解像度バージョンではないことに注意してください。サイトにアップロードするときにフル解像度の画像を使用しました。(resolution image)
OnlineOCR
OnlineOCR.netは、私のテストで非常に良い結果をもたらした、クリーンでシンプルなサイトです。私が気に入っている主な点は、あちこちに大量の広告がないことです。これは通常、この種のニッチなサービス(niche service)サイトに当てはまります。

開始するには、ファイルを選択し、アップロードが完了するまで待ちます。(file and wait till)このサイトの最大アップロードサイズは100MBです。無料アカウントに登録すると、アップロードサイズの拡大、複数ページのPDF(PDFs)、さまざまな入力言語、1時間あたりのコンバージョン数の増加など、いくつかの追加機能を利用できます。
次に、入力言語(input language)を選択してから、出力形式(output format)を選択します。Word、Excel、またはプレーンテキスト(Plain Text)から選択できます。[(Click)変換(Convert)]ボタンをクリックすると、ボックスの下部にダウンロードリンク(download link)とともにテキストが表示されます。
テキストだけが必要な場合は、ボックスからコピーして貼り付けるだけです。(copy and paste)ただし、元のドキュメントのレイアウトを維持するという驚くほど優れた機能を備えているため、 Wordドキュメント(Word document)をダウンロードすることをお勧めします。
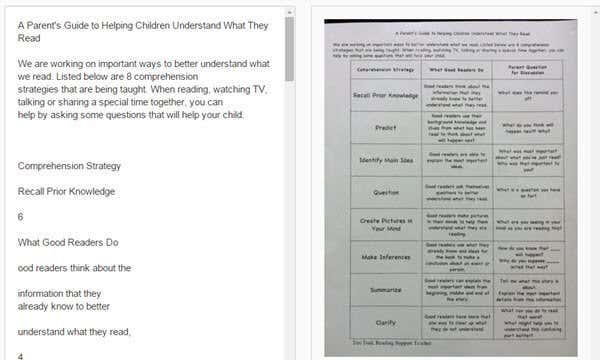
たとえば、2回目のテストでWordドキュメント(Word document)を開いたとき、画像のように、ドキュメントに3列のテーブルが含まれていることに驚きました。

すべてのサイトの中で、これは群を抜いて最高でした。多くの変換を行う必要がある場合は、登録する価値があります。
完全を期すために、各サービスによって作成された出力ファイルにもリンクして、結果を自分で確認できるようにします。OnlineOCRの結果は次のとおりです:Test1DocおよびTest2Doc(Test1 Doc and Test2 Doc)。
これらのWord文書をコンピューターで開くと、インターネット(Internet and editing)からのものであり、編集が無効になっていることを示すメッセージがWordに表示されることに注意してください。(Word)Wordは(Word doesn)インターネット(Internet)からのドキュメントを信頼せず、ドキュメントを表示するだけの場合は編集を有効にする必要がないため、これはまったく問題ありません。
i2OCR
かなり良い結果をもたらした別のサイトはi2OCRでし(i2OCR)た。プロセスは非常に似ています。言語とファイルを選択してから、[テキストの抽出(Extract Text)]を押します。

このサイトは少し時間がかかるので、ここで1、2分待つ必要があります。また、手順2(Step 2)では、プレビューで画像が正しい向きで表示されていることを確認してください。表示されていない場合は、出力として大量のジブリッシュが表示されます。どういうわけか、私のiPhoneからの画像は私のコンピューターでは縦向きモード(portrait mode)で表示されていましたが、このサイトにアップロードしたときは横向きでした。
写真編集アプリで画像を手動で開き、90度回転させてから、縦向きに回転させてから、もう一度保存する必要がありました。完了したら、下にスクロールすると、(Once)ダウンロードボタン(download button)とともにテキストのプレビューが表示されます。
このサイトは、最初のテストの出力ではかなりうまくいきましたが、列レイアウト(column layout)を使用した2番目のテストではうまくいきませんでした。i2OCRの結果は次のとおりです:Test1DocおよびTest2Doc(Test1 Doc and Test2 Doc)。
FreeOCR
Free-OCR.comは画像を取得し、(Free-OCR.com)プレーンテキスト(plain text)に変換します。Word形式(Word format)にエクスポートするオプションはありません。ファイルを選択し、言語を選択して、[開始(Start)]をクリックします。
サイトは高速で、かなり迅速に出力を取得できます。リンクをクリックするだけで、(Just click)テキストファイル(text file)をコンピュータにダウンロードできます。

以下で説明するNewOCR(NewOCR)と同様に、このサイトはドキュメント内のすべてのTを大文字にします。なぜそうなるのかわかりませんが、奇妙な理由で、このサイトとNewOCR(site and NewOCR)の両方がこれを行いました。それを変更することは大したことではありませんが、それはあなたが本当にする必要がない退屈なプロセスです。
FreeOCRの結果は次のとおりです:Test1DocおよびTest2Doc(Test1 Doc and Test2 Doc)。
ABBYY FineReader Online
FineReader Onlineを使用するには、アカウントに登録する必要があります。これにより、最大10ページのOCRを15日間無料で試用できます。数ページに対して1回限りのOCR(OCR)を実行するだけでよい場合は、このサービスを使用できます。登録後、確認メールの(confirmation email)確認リンク(verify link)をクリックしてください。(Make)

上部にある[認識]をクリックし、[(Recognize)アップロード(Upload)]をクリックしてファイルを選択します。言語と出力形式を選択し、下部にある[認識(Recognize)]をクリックします。このサイトのインターフェースはすっきりしていて、広告もありません。
私のテストでは、このサイトは最初のテストドキュメント(test document)からテキストを取得できましたが、 Wordドキュメント(Word doc)を開いたときは絶対に巨大だったので、もう一度やり直して、出力形式(output format)としてプレーンテキスト(Plain Text)を選択しました。
列を使用した2番目のテストでは、Word文書(Word document)が空であり、テキストも見つかりませんでした。そこで何が起こったのかはわかりませんが、単純な段落以外は処理できないようです。FineReaderの結果は次のとおりです:Test1DocおよびTest2Doc。
NewOCR
次のサイトであるNewOCR.comは問題ありませんでしたが、最初のサイトほど良くはありませんでした。まず、広告がありますが、ありがたいことに1トンではありません。最初にファイルを選択してから、[プレビュー(Preview)]ボタンをクリックします。

次に、画像を回転させて、テキストをスキャンする領域を調整できます。これは、スキャナーが接続されたコンピューターでスキャンプロセス(scanning process)がどのように機能するかとほとんど同じです。

ドキュメントに複数の列がある場合は、 [ページレイアウト分析( Page layout analysis)]ボタンをオンにすると、テキストが列に分割されます。OCRボタンを(OCR button)クリックし(Click)、完了するまで数秒待ってから、ページが更新されたら一番下までスクロールします。
最初のテストでは、すべてのテキストが正しく取得されましたが、何らかの理由で、ドキュメント内のすべてのTが大文字になっています。なぜそうなるのか分かりませんが、そうしました。ページ分析(page analysis)を有効にした2番目のテストでは、ほとんどのテキストが取得されましたが、レイアウトは完全にオフでした。
NewOCRの結果は次のとおりです:Test1DocおよびTest2Doc。
結論
ご覧のとおり、残念ながら、無料ではほとんどの場合、あまり良い結果が得られません。最初に言及したサイトは、すべてのテキストを認識するのに優れた機能を果たしただけでなく、元のドキュメントの形式を維持することができたため、群を抜いて最高です。
ただし、テキストだけが必要な場合は、上記のほとんどのWebサイトでそれを実行できるはずです。ご不明な点がございましたら、お気軽にコメントください。楽しみ!
5 Free Online OCR Services Tested and Reviewed
Have a PDF document or an image that you would like to convert to text? Recently, someone sent me a document in the mail that І needed to edіt and send baсk with corrections. The person сouldn’t locate a digital copy, so I wаs tasked with getting all that text into digital format.
There was no way I was going to spend hours typing everything back in, so I ended up taking a nice high-quality picture of the document and then burned my way through a bunch of online OCR services to see which one would give me the best results.
In this article, I’ll go through a couple of my favorite sites for OCR that are free. It’s worth noting that most of these sites provide a basic free service and then have paid options if you want extra features like bigger images, multi-page PDF documents, different input languages, etc.
It’s also good to know beforehand that most of these services will not be able to match the formatting of your original document. These are mainly for extracting text and that’s it. If you need everything to be in a specific layout or format, you’ll have to manually do that once you get all the text from the OCR.
In addition, the best results for getting the text will come from documents with a 200 to 400 DPI resolution. If you have a low DPI image, the results will not be as good.
Lastly, there were a lot of sites I tested that just didn’t work. If you Google free online OCR, you’ll see a bunch of sites but several of the sites in the top 10 results didn’t even complete the conversion. Some would time out, other would give errors and some just got stuck on the “converting” page, so I didn’t even bother to mention those sites.
For each site, I tested two documents to see how well the output would be. For my tests, I simply used my iPhone 5S to take a picture of both documents and then uploaded them directly to the websites for conversion.
In case you want to see what the images looked like that I used for my test, I have attached them here: Test1 and Test2. Note that these are not the full resolution versions of the images taken from the phone. I used the full resolution image when uploading to the sites.
OnlineOCR
OnlineOCR.net is a clean and simple site that delivered very good results in my test. The main thing I like about it is that it doesn’t have tons of ads all over the place, which is usually the case with these kinds of niche service sites.
To start, select your file and wait till it finishes uploading. The max upload size for this site is 100 MB. If you register for a free account, you get a few extra features like the bigger upload size, multi-page PDFs, different input languages, more conversions per hour, etc.
Next, choose your input language and then choose the output format. You can choose from Word, Excel, or Plain Text. Click the Convert button and you’ll see the text displayed at the bottom in a box along with a download link.
If all you want is the text, just copy and paste it from the box. However, I suggest you download the Word document because it does a surprisingly great job of keeping the layout of the original document.
For example, when I opened the Word document for my second test, I was surprised to find that the document included a table with three columns, just like in the image.
Out of all the sites, this one was the best by far. It’s totally worth registering for if you need to do a lot of conversions.
For completeness, I am also going to link to the output files created by each service so you can see the results for yourself. Here are the results from OnlineOCR: Test1 Doc and Test2 Doc.
Note that when opening these Word documents on your computer, you’ll get a message in Word stating that it’s from the Internet and editing has been disabled. That is perfectly OK because Word doesn’t trust documents from the Internet and you really do not have to enable editing if you just want to view the document.
i2OCR
Another site that gave pretty good results was i2OCR. The process is very similar: choose your language, file, and then press Extract Text.
You’ll have to wait a minute or two here because this site takes a bit longer. Also, in Step 2, make sure that your image is showing right-side up in the preview, otherwise you’ll get a bunch of gibberish as output. For some reason, the images from my iPhone were showing in portrait mode on my computer, but landscape when I uploaded to this site.
I had to manually open the image in a photo editing app, rotate it 90 degrees, then rotate it back to portrait and then save it again. Once complete, scroll down and it’ll show you a preview of the text along with a download button.
This site fared pretty well with the output for the first test, but didn’t do so well with the second test that had the column layout. Here are the results from i2OCR: Test1 Doc and Test2 Doc.
FreeOCR
Free-OCR.com will take your images and convert them into plain text. It does not have an option to export to Word format. Choose your file, select a language and then click Start.
The site is fast and you’ll get the output fairly quickly. Just click on the link to download the text file to your computer.
As with NewOCR mentioned down below, this site capitalizes all the T’s in the document. I have no idea why it would do that, but for some odd reason this site and NewOCR both did this. It’s not a big deal to change it, but it’s a tedious process you really shouldn’t have to do.
Here are the results from FreeOCR: Test1 Doc and Test2 Doc.
ABBYY FineReader Online
In order to use FineReader Online, you have to register for an account, which gets you a 15-day free trial to OCR up to 10 pages for free. If you only need to do a one-time OCR for a couple of pages, then you can use this service. Make sure that you click the verify link in the confirmation email after you register.
Click on Recognize at the top and then click Upload to select your file. Choose your language, output format and then click Recognize at the bottom. This site has a clean interface and no ads too.
In my tests, this site was able to grab the text from the first test document, but it was absolutely enormous when I opened the Word doc, so I ended up doing it again and choosing Plain Text as the output format.
For the second test with the columns, the Word document was empty and I couldn’t even find the text. Not sure what happened there, but it doesn’t seem to be able to handle anything other than simple paragraphs. Here are the results from FineReader: Test1 Doc and Test2 Doc.
NewOCR
The next site, NewOCR.com, was OK, but not nearly as good as the first site. Firstly, it’s got ads, but thankfully not a ton. You first select your file and then click the Preview button.
You can then rotate the image and adjust the area where you want to scan for text. It’s pretty much kind of like how the scanning process works on a computer with an attached scanner.
If the document has multiple columns, you can check the Page layout analysis button and it will try to split the text up into columns. Click the OCR button, wait a few seconds for it to complete and then scroll down to the bottom when the page refreshes.
In the first test, it got all the text correctly, but for some reason capitalized every T in the document! No idea why it would do that, but it did. In the second test with page analysis enabled, it got most of the text, but the layout was completely off.
Here are the results from NewOCR: Test1 Doc and Test2 Doc.
Conclusion
As you can see, free doesn’t really give you very good results most of the time unfortunately. The first site mentioned is the best by far because not only did it do a great job of recognizing all the text, it also managed to retain the format of the original document.
If you just need text, though, most of the websites above should be able to do that for you. If you have any questions, feel free to comment. Enjoy!

{kind=link}
{kind=link}