PDFドキュメントからテーブルを抽出する方法
この記事では、PDFドキュメントからテーブルを抽出(extract tables from PDF documents)する方法を説明します。別々に使用したい複数のテーブルを含む多くのPDFファイルがあるかもしれません。これらのテーブルをコピーして貼り付けると、期待どおりの出力が得られない可能性があるため、適切なオプションではありません。したがって、 (Copying)PDFファイルからテーブルを抽出し、それらのテーブルを個別のファイルとして保存できる他の簡単なオプションが必要です。
これらのPDFテーブル抽出ツールのほとんどは、 (PDF table extractor tools)PDFテーブルがスキャンされた場合には役に立ちません。このような場合は、最初にPDFを検索可能(make the PDF searchable) にしてから、これらのオプションを試してください。
PDFドキュメントからテーブルを抽出する
この投稿では、PDFファイルからテーブルを抽出するための2つの無料オンラインサービスと3つの無料ソフトウェアを追加しました。
- PDFからXLSへ
- PDFtoExcel.com
- タブラ
- ByteScoutPDFマルチツール
- SejdaPDFデスクトップ。
1]PDFからXLS
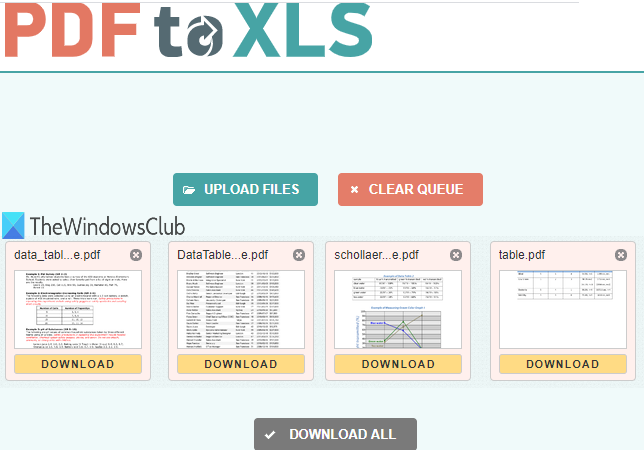
PDF to XLSは、 (XLS)PDFからテーブルを抽出するための最良のオプションの1つです。便利な2つの機能があります。20個のPDF(20 PDF)ドキュメントから一緒にテーブルをフェッチできます。また、PDFテーブルの抽出は自動的に行われます。XLSXファイルとして出力を生成します。PDFに複数のテーブルがある場合、各テーブルは出力XLSXファイルの異なるシートに個別に保存されます。
(Open the homepage)このサービスのホームページを開きます。その後、PDFファイルをドラッグアンドドロップするか、 [ファイルのアップロード(UPLOAD FILES)]ボタンを使用します。アップロードされた各PDFは、 XLSX(PDF)形式のファイルに自動的に変換されます。出力ファイルの準備ができたら、それらを1つずつダウンロードするか、すべての出力ファイルを含むZIPファイルをダウンロードできます。(ZIP)
2] PDFtoExcel.com

PDFtoExcel.comサービスは、一度に1つのPDFからテーブルを抽出できますが、 (PDF)PDFをアップロードするための複数のプラットフォームをサポートしています。PDFをアップロードするために、 OneDrive、デスクトップ(desktop)、Googleドライブ(Google Drive)、およびDropboxプラットフォームをサポートします。また、変換プロセスは自動です。
このサービスのホームページはこちら(here)です。そこで、アップロードオプションを選択してPDFを追加します。その後、PDFを自動的にアップロードしてExcel(XLSX)ファイルに変換します。出力の準備ができると、 PDF(PDF)テーブルを含む出力ファイルを保存するためのダウンロードリンクが表示されます。
注:(Note: )このサービスでは、スキャンしたPDFファイルからテーブルを抽出することもできると記載されていますが、私には機能しませんでした。スキャンしたPDF(PDF)でも試すことができます。
3]タブラ

Tabulaは、 (Tabula)PDFに存在するテーブルを自動的に検出し、それらのテーブルをTSV、JSON、またはCSVファイルとして保存できる強力なソフトウェアです。PDFテーブルごとに個別のCSVファイルを保存するオプション、またはすべてのテーブルを1つのCSVファイルに保存するオプションを選択できます。
このオープンソースの(open-source)PDFテーブルエクストラクタをダウンロードするには、ここをクリックしてください(click here)。また、Java(requires Java)を実行して正常に使用する必要があります。
ダウンロードしたZIP(ZIP)ファイルを解凍し、tabula.exeファイルを実行します。デフォルトのブラウザでページが開きます。ページが開いていない場合は、ブラウザにhttp:// localhost:8080を追加し、Enterキー(Enter)を押します。
これで、[参照]オプションを使用して(Browse)PDFを追加できるインターフェイスが表示されます。その後、インポート(Import)ボタンを押します。PDFを追加すると、そのインターフェイスにPDFページが表示され(PDF)ます。
[テーブル(Autodetect Tables)の自動検出]ボタンを使用すると、そのPDFに存在するすべてのテーブルが自動的に強調表示されます。特定のテーブルを選択して、テーブルを手動で強調表示することもできます。必要に応じて、選択したテーブル(remove selected tables)を削除することもできます。
これは、必要なテーブルのみを保存するのに役立ちます。PDFテーブルが強調表示されたら、[抽出されたデータのプレビューとエクスポート(Preview & Export Extracted Data)]ボタンをクリックします。
最後に、上部にあるドロップダウンメニューを使用して出力形式を選択し、[エクスポート(Export)]ボタンを押します。これにより、 PDFテーブルが選択した出力形式のファイルに保存されます。
4]ByteScoutPDFマルチツール
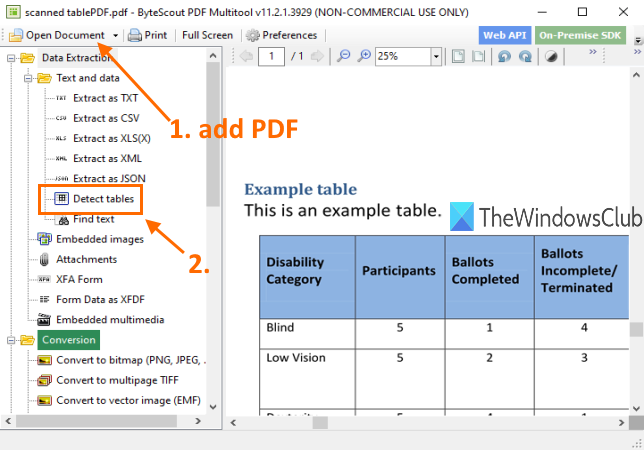
名前が示すように、このソフトウェアには複数のツールが付属しています。PDFをマルチページTIFF(convert PDF to multipage TIFF)に変換する、PDFドキュメントを回転(rotate PDF document)する、PDFを検索不能(make PDF unsearchable)にする、PDFを最適化(optimize PDF)する、PDFに画像を追加する(add an image to PDF)などのツールがあります。PDFテーブル検出機能もあります。これはかなり素晴らしいです。このツールの利点は、スキャンしたPDFからもテーブルを抽出(extract tables from scanned PDF)できることです。複数のページのテーブルを検出し、それらのテーブルをCSV、XLS、XML、TXT、またはJSON形式のファイルとして抽出できます。抽出する前に、ページ範囲(page range)を設定することもできます指定されたページからのみテーブルを抽出します。
ここで(here)このソフトウェアを入手できます。非営利目的でのみ無料(free for non-commercial use)です。インストール後、このソフトウェアを実行し、[ドキュメントを開く]オプションを使用して(Open Document)PDFを追加します。その後、上の画像で強調表示されているように、テーブルの検出(Detect tables)ツールをクリックします。このツールは、データ抽出(Data Extraction)カテゴリにあります。
テーブルを検出するための条件を設定できるボックスが開きます。たとえば、列、行の最小数、テーブル間の最小改行を設定したり、テーブル検出モードを境界付きまたは境界なしのテーブルに設定したりできます。オプションを使用するか、デフォルト設定を維持します。
その後、そのボックスの[次のテーブルの検出(Detect next table)]ボタンを押します。現在のページのテーブルを識別して選択します。このようにして、別のページに移動して、より多くのテーブルを検出できます。
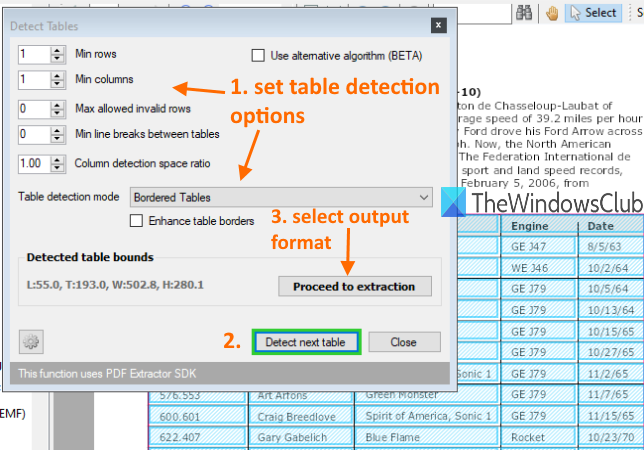
完了したら、[抽出に進む(Proceed to extraction)]ボタンを使用して、出力形式を選択します。最後に、オプションを使用して、現在のページからテーブルを保存するか、ページ範囲を定義して、出力を保存できます。
このツールは満足のいく出力を提供します。ただし、 PDF(PDF)内の他のコンテンツを検出し、複数のページからテーブルを抽出できない場合があります。その場合は、テーブルを1つずつフェッチして保存するために使用する必要があります。
5]SejdaPDFデスクトップ
SejdaPDFデスクトップ(Sejda PDF Desktop)も多目的ソフトウェアです。PDFの最適化または圧縮、PDF(compress PDF)への透かしの追加、PDFからの制限の削除、 (remove restrictions from PDF)PDFドキュメントの編集などが可能です。ただし、無料プランには制限があります。無料プランでは、1日あたり3つのタスクしか実行できません。また、PDFのサイズ制限は50MBまたは10ページ(10 pages)です。
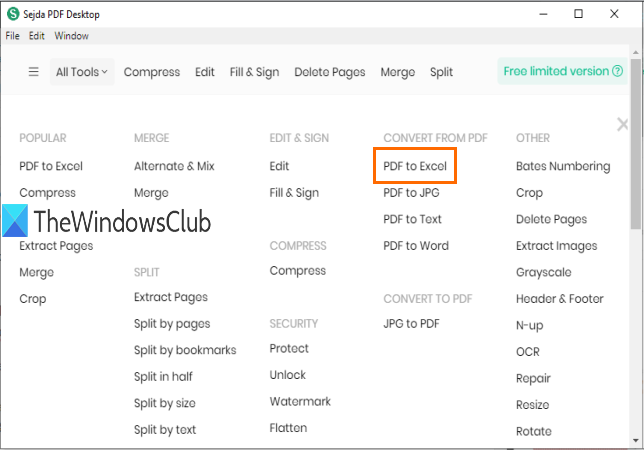
PDFからExcel(PDF to Excel)への変換ツールを使用してPDFテーブルを抽出できます。PDFページのテーブルを自動的に検出し、それらのテーブルをXLSXまたはCSVとして保存できます。
そのダウンロードリンクはこちら(here)です。インストール後、メインインターフェイスからPDFtoExcel(PDF)ツールを使用します。(Excel)そのツールを選択した後、 [ PDFファイルの選択(Choose PDF files)]ボタンを使用します。無料プランに追加できるPDFは1つだけです。
PDFを追加すると、[ PDFをCSV(Convert PDF to CSV)に変換]ボタンと[PDFをExcel(Convert PDF to Excel)に変換]ボタンが表示されます。ボタンを使用すると、出力をPCの目的の場所に保存できます。
そのPDFテーブル検出ツールは優れています。テーブルを手動で検出する必要はありません。それでも、他のテキストコンテンツをPDFテーブルとして含め、出力に保存する場合があります。しかし、全体的な結果は良好です。
それで全部です。
これらは、PDFからテーブルを抽出するためのいくつかの優れたツールです。Tabulaソフトウェアは、他のツールよりも効果的です。それでも、すべてのツールを試して、どれが役立つかを確認できます。
同様の読み取り:(Similar reads:)
- PDFから添付ファイルを抽出する(Extract attachments from PDF)
- PDFからハイライトされたテキストを抽出します(Extract highlighted text from PDF)。

About the author
私はユタ大学でコンピュータ エンジニアリングを卒業し、ソフトウェア開発と Windows 開発で 10 年以上の経験があります。PDF や Office ドキュメントを扱った経験があり、iOS や Android プラットフォームを使用してガジェットを作成した経験もあります。
Related posts
Document Converter、PDF、DOCX、DOCX、RTF、TXT、HTMLファイル
PPS fileとは何ですか? PPSからPDFをWindows 11/10に変換する方法
PDF text Windows 10でファイルを編集または保存するときに消えます
クラウドベースのBest Free PDF Editor Online Tools
PDFファイルを編集するための無料PDF Editor Online Tool - PDF Yeah
Compress PDF Software:Compress PDF PDF Reducer onlineツールを使用したファイル
Optimize、Windows 10でPDF File sizeを圧縮し縮小する
検索可能なPDFへのConvert Scanned PDFの方法?
Windows 10のためのCutePDFを使って文書をPDFに変換する方法
7-PDF Website Converter:PDFからConvert Web Pages
Remove PDF Restrictions無料software or online toolsを使用する
Windows 10のPDF fileサイズを縮小するためのPDF Compressor
ブラウザを使用してGoogle Docsを使用してDocumentsをPDFに変換する方法
PRIMA Rapid Image Viewerを介して画像とPDF Docsを素早く表示します
Encrypt PDF file Windows PCの場合はPDF Page Lockを使用してください
PDF documentをWindowsのマルチキャリアTIFF imageに変換する方法
Edge browserのPDFs for PDFsの2ページLayoutを有効にする方法
Best PDF word counter software and online tools
PDF Fixer ToolのPDF Fixer ToolのPDFを修理する方法Windows 10
Google Driveを使用してExcel fileをPDF onlineに変換する方法